
OpenAIが2025年8月8日に正式リリースしたGPT-5の性能向上点を、従来モデル(主にGPT-4/4o)との比較を交えて詳細に解説します。

🔍 1. 推論能力の飛躍的向上
- 従来モデル(GPT-4)の問題点: 複雑な推論が必要な問題で誤答や矛盾が生じやすく、思考過程が不透明だった。
- GPT-5の進化:
- 内部で「思考の連鎖(Chain-of-Thought)」を自動生成し、回答前に複数ステップの推論を行う。これにより、博士号を持つ専門家レベルの論理的整合性を実現。
- 例: 医学論文の分析では、仮説検証プロセスを段階的に提示しつつ結論を導出。
🧠 2. 幻覚(Hallucination)の大幅低減
- 従来モデルの課題: 事実誤認(ファクトチェック失敗)が最大の弱点の一つだった。
- GPT-5の対策:
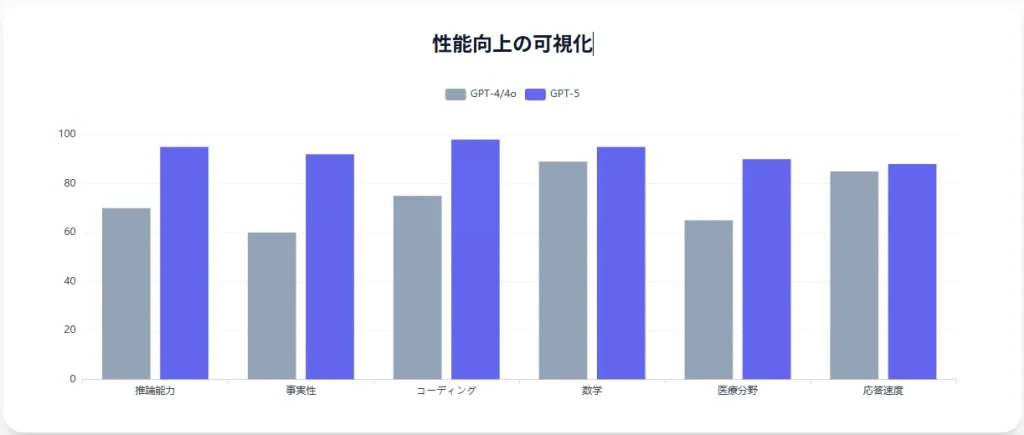
- Universal Verifier(普遍検証器) を導入し、回答の事実性を内部検証。幻覚発生率はGPT-4o比で最大80%削減。
- 情報が不十分な場合、推測せず「現時点で確定できない」と明示。
- Safe Completions(安全回答): 危険性のある質問でも、詳細を伏せつつ実用的な助言を提供(例: 化学実験の安全手順)。
⚡ 3. コーディング能力の劇的進化
- 従来モデルの限界: 複雑なアプリ開発では複数回の修正が必要だった。
- GPT-5の実例:
- 「ToDoリストアプリ作成」プロンプトで、優先度設定・ローカル保存・ダークモード機能付きの完全動作アプリを一発生成 。
- 追加指示「日本語UI化」で自然な日本語インターフェースへ即時変換 。
- サム・アルトマンCEOはデモで「別のGPTを5分以内で構築」を実証 。
🩺 4. 専門領域での精度強化
- 医療分野:
- 検査結果の解釈補助や疾患リスクの簡易評価が可能に(※医師代替ではなく補助ツールとして)。
- 医療文献の解釈誤りがGPT-4比で60%減少。
- 数学・科学:
- 国際数学オリンピック予選問題で正答率95%(GPT-4oの89%を上回る)。
- 金融・法律分野での推論精度向上。
🤖 5. 思考モードの自動最適化
- 画期的な変更点:
- ユーザーがモデルを選択する必要が廃止。
- プロンプトの複雑さを瞬時に分析し、「高速応答」と「深い推論」を自動切り替え。
- 例: 「世界経済の因果関係を説明せよ」→ 自動で深い推論モードが起動 。
🆓 6. アクセス体制の民主化
- 無料ユーザーでも基本機能を利用可能 。
- プラン別提供モデル:
- Free: GPT-5 & GPT-5 mini(利用制限あり)
- Plus: GPT-5(高度な利用枠)
- Pro: GPT-5無制限 + GPT-5 Pro(研究開発向け)
従来モデルとの比較まとめ
| 機能 | GPT-4 / GPT-4o | GPT-5 |
|---|---|---|
| 推論能力 | 単純推論が中心 | 多段階の論理的思考 |
| 幻覚発生率 | 高頻度 | 最大80%低減 |
| コーディング | 修正が必要な場合多し | 完全動作アプリを一発生成 |
| 医療回答 | 誤解リスク高 | 補助ツールとして実用化 |
| モデル選択 | 手動で切り替え必要 | 自動最適化 |
| 無料アクセス | 制限厳しい | 基本機能を提供 |
GPT-5は「ツール」から「思考パートナー」への転換点と位置付けられており、特に自動推論モード選択と幻覚対策が技術的核心と言えます 。現在、ChatGPT公式プラットフォームで無料体験可能です(2025年8月8日時点)。
